1. Kubernetes information: kubectl explain <kubernetes_term>
e.g. kubectl explain pods

2. Get the cluster nodes: kubectl get nodes -o wide
e.g.

3. Get Node information: kubectl describe node <node_name>
e.g. kubectl describe node vra-01.vcloud.local

4. Check running pods on nodes: kubectl -n prelude get pods -o wide
e.g.

5. Check Resource usage of Pods: kubectl -n prelude top pod
e.g.

6. Get detailed pod information: kubectl -n prelude describe pods <pod_name>
e.g. kubectl -n prelude describe pods vco-app-6ff5d79cd8-s9mfb

7. Live log review: kubectl -n prelude logs <pod_name> <container_name_if_applicable> | less
e.g. kubectl -n prelude logs vco-app-6ff5d79cd8-s9mfb vco-server-app | less

NOTE: We can also pipe the logs through less & grep for errors:
kubectl -n prelude logs tango-blueprint-service-app-57dbb4fc4b-hxdkm | less | grep ERROR
8. Restart a pod (if stuck): kubectl -n prelude delete pods <pod_name>
e.g. kubectl -n prelude delete pods vco-app-6ff5d79cd8-s9mfb

9. Scale pods: kubectl scale –replicas=<int> -n prelude deployment <deployment_name>
e.g. kubectl scale –replicas=3 -n prelude deployment vco-app

10. Open a shell to a specific pod: kubectl -n <namespace> exec -it <pod_name> — /bin/sh
e.g. kubectl -n prelude exec -it vco-app6ff5d79cd8-s8mfb — /bin/sh

11. Execute commands on a pod: kubectl -n <namespace> exec <pod_name> — <command>
e.g. kubectl -n prelude exec vco-app6ff5d79cd8-s8mfb — uptime

12. Restart the cluster:
/opt/scripts/deploy.sh –onlyClean
/opt/scripts/deploy.sh
13. Configuration Files:
All configuration files for vRA/vRO pods are contained within the following directory: /opt/charts

Within each sub-directory of /opt/charts there is a templates directory that can be useful when troubleshooting multiple pods that aren’t running. The file to look for within this directory is the dependencies.yaml as within this file any pod dependencies are listed. Using this we can identify a possible root cause for the issue.

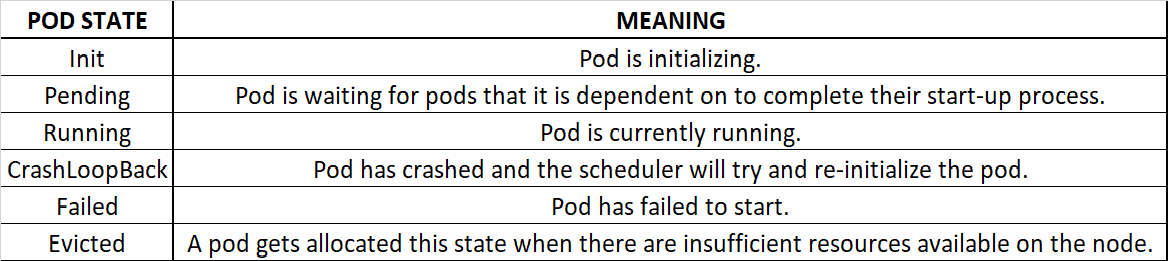
13. Pod Status & Meaning: